How it works
High-availability Namespaces are in Public Preview for Temporal Cloud.
In traditional active/active replication, multiple nodes serve requests and accept writes simultaneously, ensuring strong synchronous data consistency. In contrast, with a Temporal Cloud high-availability Namespace, only the active zone accepts requests and writes at any given time. Workflow history events are written to the active zone first and then asynchronously replicated to the standby zone replica, ensuring that the replica remains in sync.
| Before failover | After failover |
|---|---|
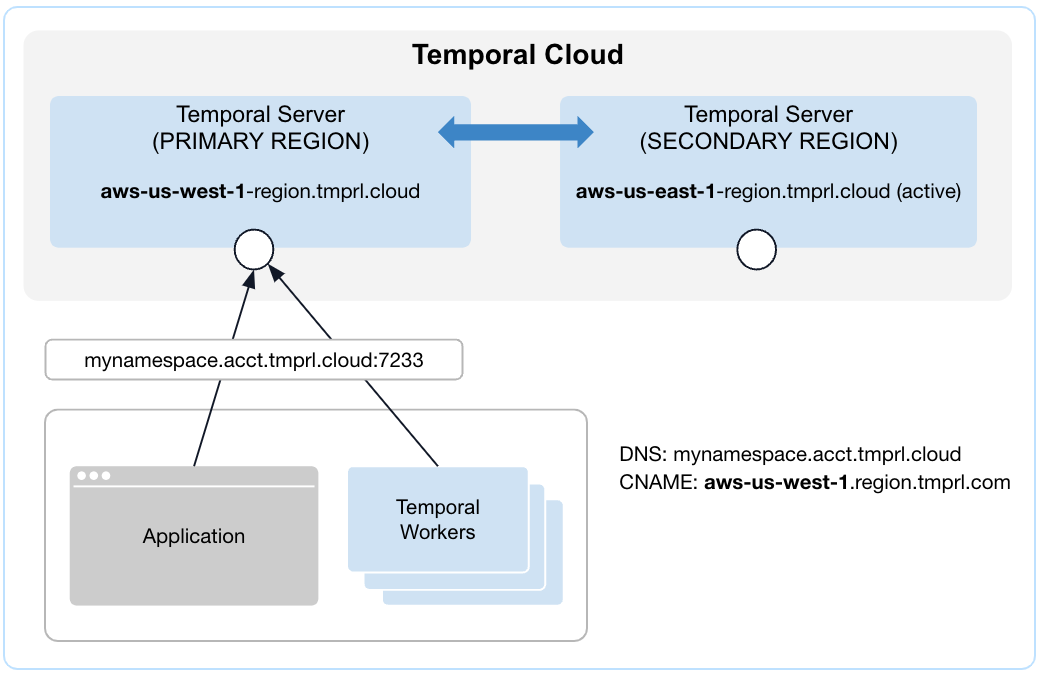 | 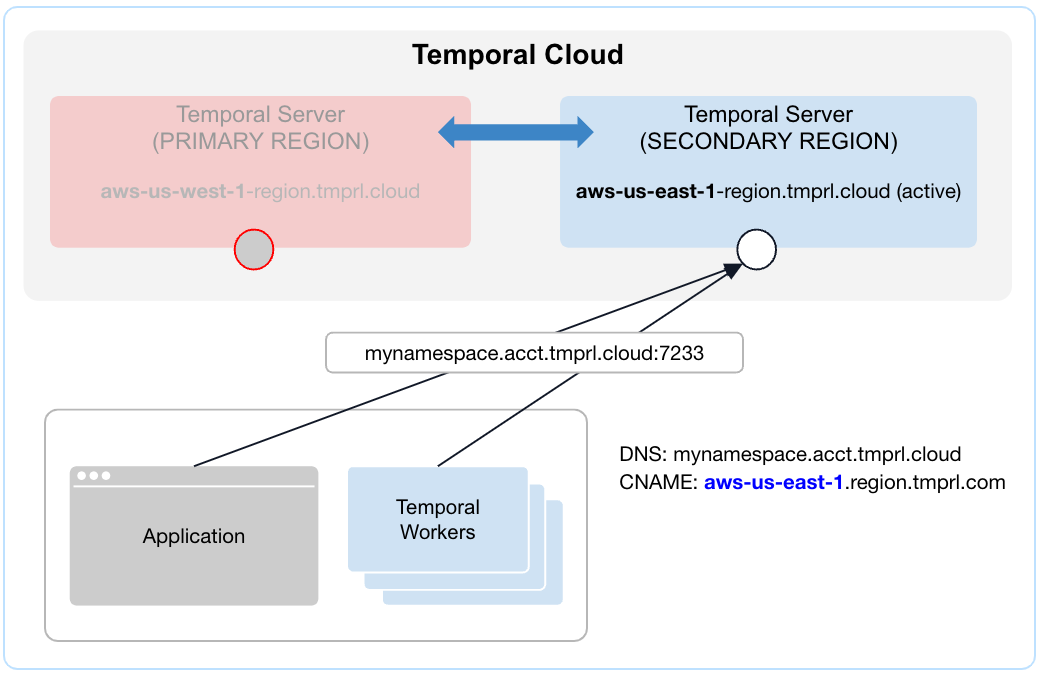 |
Failovers
A failover shifts Workflow Execution processing from an active Temporal Namespace region to a standby Temporal Namespace region during outages or other incidents. Standby Namespace regions use replication to duplicate data and prevent data loss during failover.
What happens during the failover process?
Temporal Cloud initiates a Namespace failover when it detects an incident or outage that raises error rates or latency in the active region of a multi-region Namespace. The failover shifts Workflow processing to a standby region that isn’t affected by the incident. This lets existing Workflows continue and new Workflows start while the incident is fixed. Once the incident is resolved, Temporal Cloud performs a "failback" by shifting Workflow Execution processing back to the original region.
You can test the failover of your multi-region Namespace by manually triggering a failover using the UI page or the 'tcld' CLI utility. In most scenarios, we recommend you let Temporal handle failovers for you.
Health Checks
How does Temporal detect failover conditions?
Temporal Cloud automates failovers by performing internal health checks. This process monitors your request error rates, latencies, and any infrastructure issues that might cause service disruptions, such as request timeouts. It automatically triggers failovers when these indicators exceed our allowed thresholds.
Replication lag
Multi-region Namespaces use asynchronous replication between regions. Workflow updates in the active region, along with associated history events, are transmitted to the standby region with a short delay. This delay is called the replication lag. Temporal Cloud strives to maintain a P95 replication delay of less than 1 minute. In this context, P95 means 95% of requests are processed faster than this specified limit.
Replication lags mean a forced failover may cause Workflows to rollback in progress. Lags may also cause recently started Workflows to be temporarily unavailable until the active region recovers. Temporal event versioning and conflict resolution mechanisms help guarantee that the Workflow Event History can be replayed. Critical operations like Signals won't get lost.
Failover scenarios
The Temporal Cloud failover mechanism supports several modes to execute Namespace failovers. These modes include graceful failover ("handover"), forced failover, and a hybrid mode. The hybrid mode is Temporal Cloud’s default Namespace behavior.
Graceful failover (handover)
In this mode, replication tasks are fully processed and drained. Temporal Cloud pauses traffic to the Namespace before the failover. This prevents the loss of progress and avoids data conflicts. The Namespace experiences a short period of unavailability, defaulting to 10 seconds.
During this period, existing Workflows stop progress. Temporal Cloud returns a "Service unavailable error", which is retried by SDKs. State transitions will not happen and tasks are not dispatched. User requests like start/signal workflow will be rejected while operations are paused during handover.
This mode favors consistency over availability.
Forced failover
In this mode, a Namespace immediately activates in the standby region. Events not replicated due to replication lag will undergo conflict resolution upon reaching the new active region.
This mode prioritizes availability over consistency.
Hybrid failover mode
While graceful failovers are preferred for consistency, they aren’t always practical. Temporal Cloud’s hybrid failover mode (the default mode) limits an initial graceful failover attempt to 10 seconds or less. During this period, existing Workflows stop progress. Temporal Cloud returns a "Service unavailable error", which is retried by SDKs. If the graceful approach doesn’t resolve the issue, Temporal Cloud automatically switches to a forced failover. This strategy balances consistency and availability requirements.
See the sections on triggering a failover, Worker deployment, and routing for more information.
Architecture
How do multi-region Namespaces work?
Multi-region Namespaces replicate Namespace metadata and Workflow Executions across connected regions. This redundancy, plus the added failover capability, provides measurable stability when dealing with outages.
A multi-region Namespace is normally active in a single region at any moment. The passive region assumes a standby role. An exception to this only occurs in the event of a network partition. In this case, you may elect to promote a standby region to active status. Caution: this action will temporarily result in both regions being active. Once the network partition resolves and communication between the regions is restored, a conflict resolution algorithm determines which region continues as the active one. This ensures only one region remains active.
Metadata replication
Updates to multi-region Namespace records automatically replicate across regions. This metadata includes configurations such as retention periods, Search Attributes, and other settings. Temporal Cloud ensures that all regions will eventually share a consistent and unified view of the Namespace metadata.
A Namespace failover, which changes the "active region" field of a Namespace record, is an update. This update is replicated via the Namespace metadata mechanism.
Workflow Execution replication
Temporal Cloud restricts certain Workflow operations to the active region:
- You may only update Workflows in the active region.
- You may only dispatch Workflow Tasks and Activity Tasks from the active region. Forward progress in a Workflow Execution can therefore only be made in the active region.
These limits mean that certain requests, such as Start Workflow and Signal Workflow, are processed by and limited to the active region. Standby regions may receive API requests from Clients and Workers. They automatically forward these requests to the active Namespace for execution.
Multi-region Namespaces provide an “all-active” experience for Temporal users. This helps limit or eliminate downtime during Namespace failover. There's a short time window from when a standby region becomes the active region to when Clients and Workers receive a DNS update. During this time requests forward from the now passive (formerly active) region to the newly active (formerly standby) region.
As Workflow Executions progress and are operated on, replication tasks created in the active region are dispatched to the standby region. Processing these replication tasks ensures that the standby region undergoes the same state transitions as the active region. This enables replicated tasks to synchronize and achieve the same state as the original tasks.
Standby regions do not distribute Workflow or Activity Tasks. Instead, they perform verification tasks to confirm that intended operations are executed so Workflows reach the desired state. This mechanism ensures consistency and reliability in the replication process across Temporal regions.
Conflict Resolution
Multi-region Namespaces rely on asynchronous event replication across Temporal regions. In the event of a non-graceful failover, replication lag may result in a temporary setback in workflow progress.
Single-region Namespaces can be configured to provide at-most-once semantics for Activities execution (when Maximum Attempts is set to 0). Multi-region Namespaces provide at-least-once semantics for execution of Activities. Completed Activities may be re-dispatched in a newly active region, leading to repeated executions.
When a Workflow Execution is updated in a new region following a failover, events from the previously active region that arrive after the failover can't be directly applied. At this point, Temporal Cloud has forked the Workflow History.
After failover, Temporal Cloud creates a new branch history for execution, and begins its conflict resolution process. The Temporal Service ensures that Workflow Histories remain valid and are replayable by SDKs post-failover or after conflict resolution. This capability is crucial for Workflow Executions to continue their forward progress.
Design your activities to succeed once and only once. This "idempotent" approach avoids process duplication that could withdraw money twice or ship extra orders by mistake. Run-once actions maintain data integrity and prevent costly errors. Idempotency keeps operations from producing additional effects. Protect your processes from accidental or repeated actions for more reliable execution.